In December 2024, myself and 4 other Deputies participated in the internal “AI Hackathon”, where teams competed to find ways to innovate the Deputy product using AI.
Our project, AI-Tract, was developed to automate the process of setting up a business’s careers page within Deputy’s Hire product.
In the following article, I’ll cover the problem space we identified, our initial solution, and then how we iterated the idea to get to our final implementation in just 5 days.
Business owners are time-poor
The primary goal of this project was to encourage buy-in to Deputy’s Hire product by automating the content creation for a business’ careers page, thereby creating a more compelling value proposition for Hire. We believed that if we could decrease the work involved when adding information to the careers page, that users would be more likely to begin using Hire, and more likely to continue using Hire – improving signups and reducing churn.
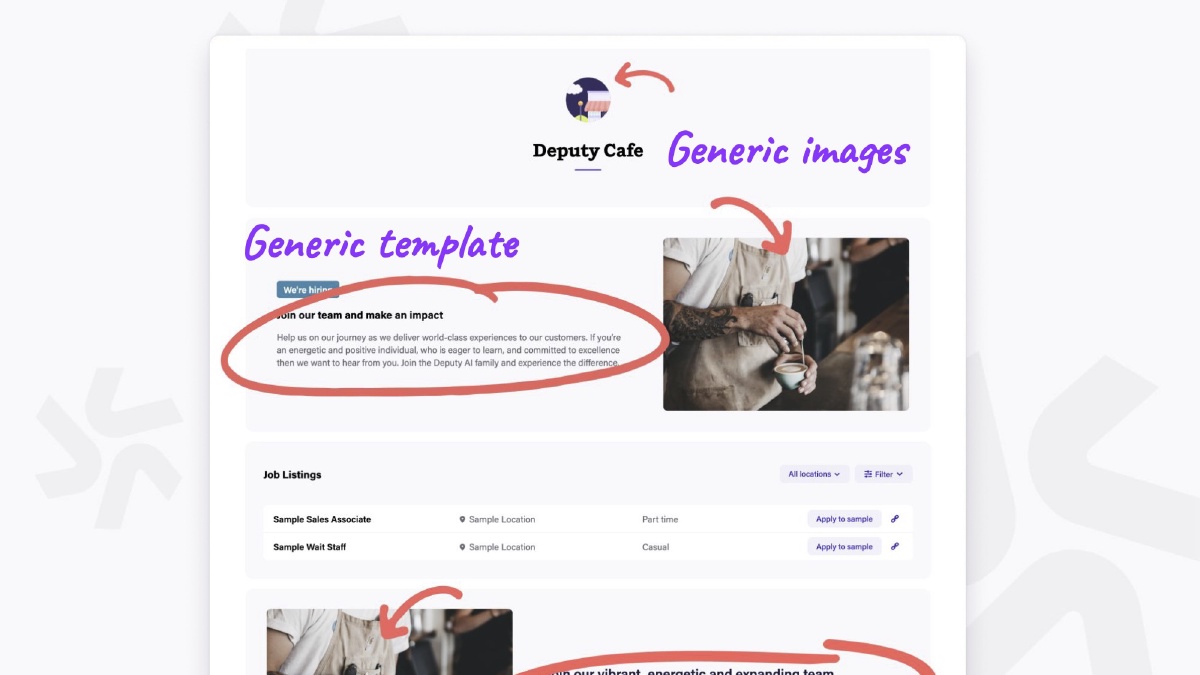
The default careers page only contains generic information and generic images. What if we could auto-fill this content?

It takes users an average of 23 days to begin editing their careers page, and only 8% of users actually edit it at all!
When we think about the user journey: First the user has to be a Deputy HR subscriber (or trial) to even access the careers page. Once they become a subscriber, the user has to perform the time-consuming task of creating some copy and finding some images which are appropriate for the business.
– Natasha, Product Manager (paraphrased)
A rough idea begins to form…
We want to demonstrate the value of the Hire product even if the user is not subscribed. We’ll call the user “prospect” since we aim to drive conversion.
To do this, we came up with the idea that the prospect could provide some information about their business (industry, number of employees, location, name) and our system could generate their careers page instantly. However, that would require collecting information via a form, which introduces additional friction. We were concerned that this could potentially impact conversion.
Next we brainstormed other ways to acquire enough information on the prospect’s business.
We considered finding this information via search engines, but we realised we can’t ensure that the correct business was selected – many businesses may share a single name, especially franchised businesses. This also can’t be applied to new prospects, since we would still be asking for business name.
It was becoming clear that we need to ask the prospect for something, but we had to minimise the amount of information collected in order to minimise friction.
Finally we came up with the idea that we would simply ask for the business website. We decided that we would limit our target market to prospects that already have a website for their business1.
The desired journey looked like this:
- Prospect can access the “careers page generator” via the public-facing
deputy.comwebsite. - Prospect submits their business website URL into the generator.
- We display their custom careers page (via iframe) with a call-to-action encouraging signing up.
Is generative AI a good fit?
Before we continue with the project, let’s take a moment to examine whether generative AI is actually a good fit.
While generative AI is powerful and is advancing at a breakneck pace, I still believe it should not be trusted to make decisions where a lot is at stake. Therefore, good use cases for generative AI will save a human time by making them more productive, instead of completely replacing a person.
In my opinion, our use case is a good fit: it doesn’t require 100% correctness, it will always have human oversight, and the end goal is not to replace a person, but rather to show the prospect the potential value they could unlock from our Hire product.
Also, as you will read about below, it will automate a mundane task for which automation was difficult prior to the popularity of large language models.
Any new technology (Gen AI, Blockchain, etc.) is only worth using if you can’t achieve the same outcome without it.
Retrieval-Augmented Generation (RAG) and why we don’t use it
Retrieval-Augmented Generation is an optimisation for Large Language Models which improves accuracy of the output for particular domains without re-training the model. One example might be a chatbot support agent which can reference articles from its company’s knowledge base.
For our project we considered using Amazon Bedrock’s Knowledge Bases, which is a managed solution that provides out-of-the-box web crawling. However, when we experimented with this, we discovered that web crawling takes a long time. For large websites it would recursively scrape all the pages on the website by following any hyperlinks it could find. This could take hours, and we would have to do it for every prospect’s website that uses the service.
With this outcome, we revised our approach. After some discussion and experimentation with the language models available in Bedrock, we determined that we can actually generate enough content for a compelling careers page by scraping a single home page or about page of the prospect’s website. Thanks to this breakthrough, we revised the implementation to provide the source code of the webpage in the prompt sent to the language model.
In the end, our prompt was this:
const PROMPT = `${pageSource}
Examine the above HTML source code for a company webpage.
We are trying to generate a career page which consist of "header", "hero" and "about" sections.
We are trying to generate a JSON file which will be used to generate the page. We are trying to generate the JSON file using the following format.
{
"header":{
"title":"",
"logo":""
},
"hero":{
"title": "",
"text":"",
"image":""
},
"about":{
"title": "",
"text":"",
"image":""
},
"socials":[
{
"key": "",
"url": ""
}
]
}
For images and logo try and extract the relevant URL from the HTML provided. If the URL is relative, prepend the base path. The HTML is scraped from ${data.scrapeURL} which contains the base path. Prioritise images where the path contains words similar to: staff, team, member. Note that sometimes, the image can be found inside the style attributed, for example: style="background-image: url("https://s3.ap-southeast-2.amazonaws.com/production.assets.merivale.com.au/wp-content/uploads/2024/10/15114711/JIMROOF_Website_640x416.jpg");"
For hero title, this should be a call-to-action statement for the reader to join the team.
For hero text use the company info to generate the text, and invite the reader to apply for a role at the company.
For about text use the company info to generate the text.
For the socials array, extract any social URLs for the company from the HTML provided. The array should be filled with objects containing a "key" and a "url" property. The "key" should be one of the following: FACEBOOK, INSTAGRAM, TIKTOK, YOUTUBE, TWITTER, LINKEDIN. If socials are not found then leave the socials array empty.
Answer explicilty in valid JSON format and do not include any comments in the JSON file. Make sure to escape all double apostrophes and special characters.
If an output cannot be generated, return the empty format example shown above.`;
Building the proof-of-concept
Which foundation model to use?
Amazon Bedrock offers a multitude of foundation models for our purposes, however after some experimentation, the best results (fewest mistakes) were achieved with Anthropic Claude 3.5 Sonnet. It was able to respond correctly to our prompts pretty much every time, and never had an issue generating responses in JSON format.
We would prompt Claude using Amazon Bedrock Runtime via API.

(Courtesy of Anthropic)
How do we work around the prompt latency?
We started with the API contracts. We would have an asynchronous execution approach – we expected that the scraping and prompting would be slower than instantaneous. We identified two endpoints to build:
POST /begin: user can submit the scrape URL, and this results in a “job” being created. It would return the job ID.GET /poll?id={job-id}: the client can call this endpoint to check the status of the job:PENDING,DONE, orFAILED. When the job isDONE, there will be additional information attached to the response: the content to render the careers page with.
For the actual careers page, we would make some slight modifications to the existing public careers page frontend and deploy this to a dummy instance (a fake business). These modifications allow the careers page to retrieve the content needed from the /poll endpoint, instead of reading from the tenant database.
Finally, on the deputy.com website, we would display a page allowing the submission of the scrape URL. This page would then poll at regular intervals until the job had completed, then display the careers page from the dummy instance within an iframe.
How can we handle dynamic and static websites?
To handle dynamic websites, we used a headless Chromium browser. We achieved this using Puppeteer. However, this increased the memory and CPU usage of the Lambda, and added an extra 10s to the crawling time.
The fastest time-to-market
We used Lambda as the compute, because it allows fast iteration and offers out-of-the-box Function URLs. For storage, we used S3 because of simplicity; we only need to read and write one known object at a time. S3 also allows us to set up an a trigger upon object creation, which starts the Lambda’s prompting stage.
Where possible, we used existing Deputy architecture. Whichever approach would take the least time to achieve our goals, we would choose – resulting in us building the Lambda-side from scratch while re-using the Deputy website and the dummy instance.
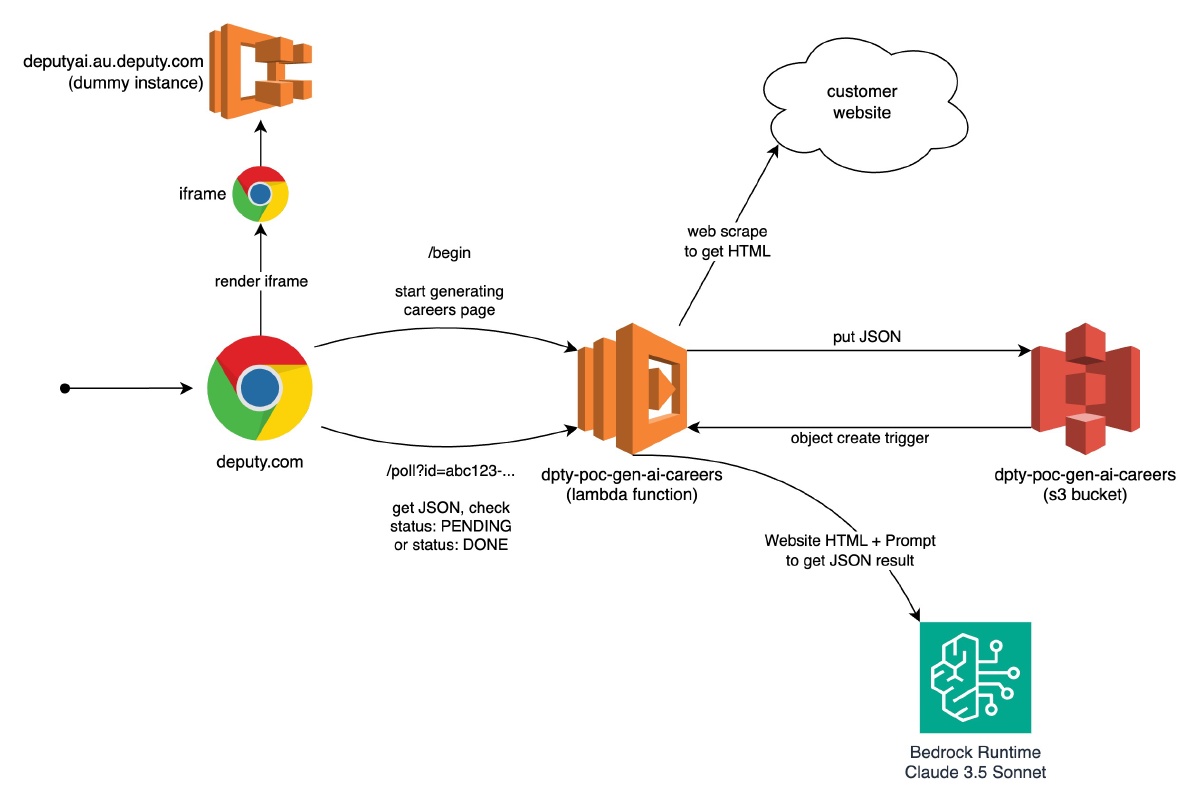
High-level architecture of our proof-of-concept, showing key components and interactions.
What we learned
We learned a lot, but the main 3 takeaways are:
- Anthropic Claude 3.5 Sonnet produces impressive results, remarkably quickly:
- It can extract information from complex varied data, such as webpage source HTML. This is where large language models really shine: extracting information from data with incredibly inconsistent structure.
- It can create valid JSON objects, even with complex nested structures. This is another strength of language models: they recognise patterns and syntax so well that they can re-create it with the desired information in the correct places.
- Prompting in plain english allows incredibly fast prototyping. This is will be the biggest driver of generative AI uptake: plain text allows for a much broader user base. We just need to be careful not to assume the language model is correct 100% of the time.
- Efficient Data Retrieval: Direct HTML fetching is faster than a web crawling knowledge base. Suitable if you need to use numerous, user-defined retrieval sources on-demand. The tradeoff is that you add latency, but for our use case, we can’t do the crawling in advance – this is the approach with lowest latency.
- Puppeteer enables effective scraping of dynamic, client-side rendered websites. E.g. Merivale’s site.
- Optimisation: the prompting can be sped up (and will consume fewer tokens) if we strip any HTML tags like
<script>,<style>, and<svg>, since these usually don’t provide any information relevant to the end result.
Project outcome
By the 4th day, we had a working system - albeit without any security, rate limiting, or ability to scale (it was a prototype after all). It took around 30 seconds to generate a personalised careers page.
Unfortunately we didn’t earn an award (robbed!), but overall it was the most fun I’ve had on the job all year. It was great to collaborate outside my usual team, with fresh faces and new perspectives.
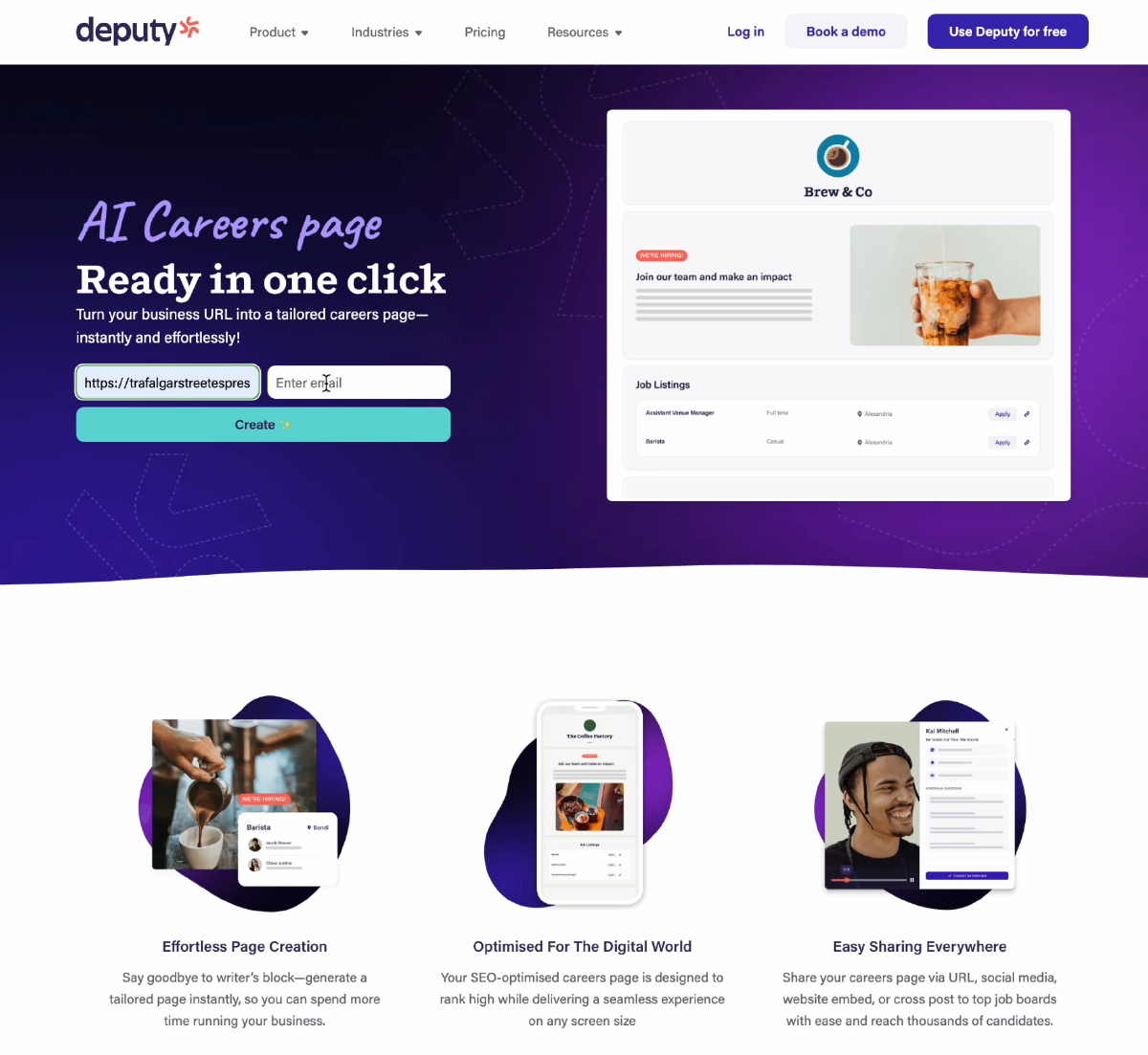
From this page, the prospect submits their website URL.
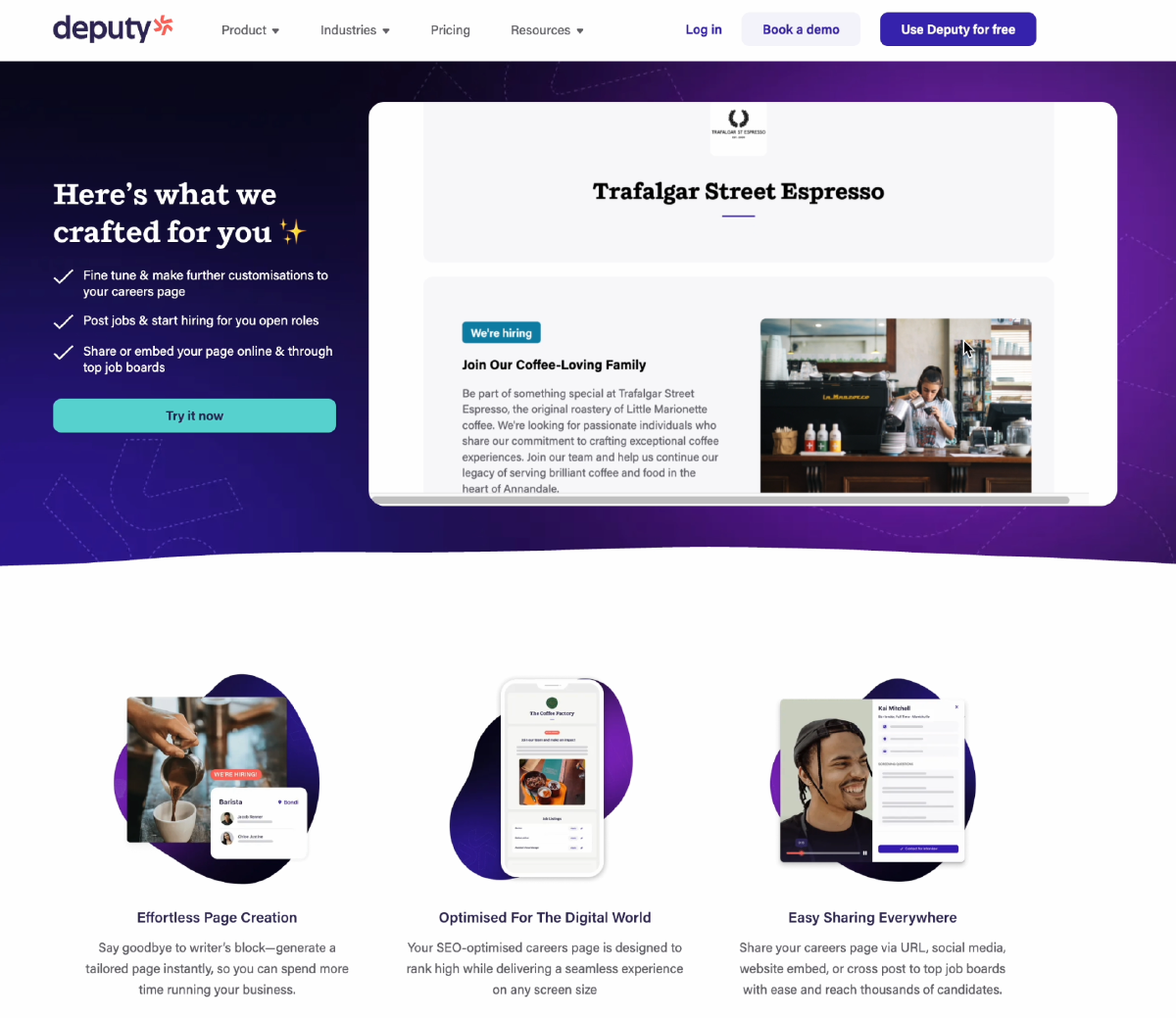
After a short wait, we show them the personalised careers page.
Sample careers pages
The following screenshots show careers pages that were generated entirely from the business’ website.
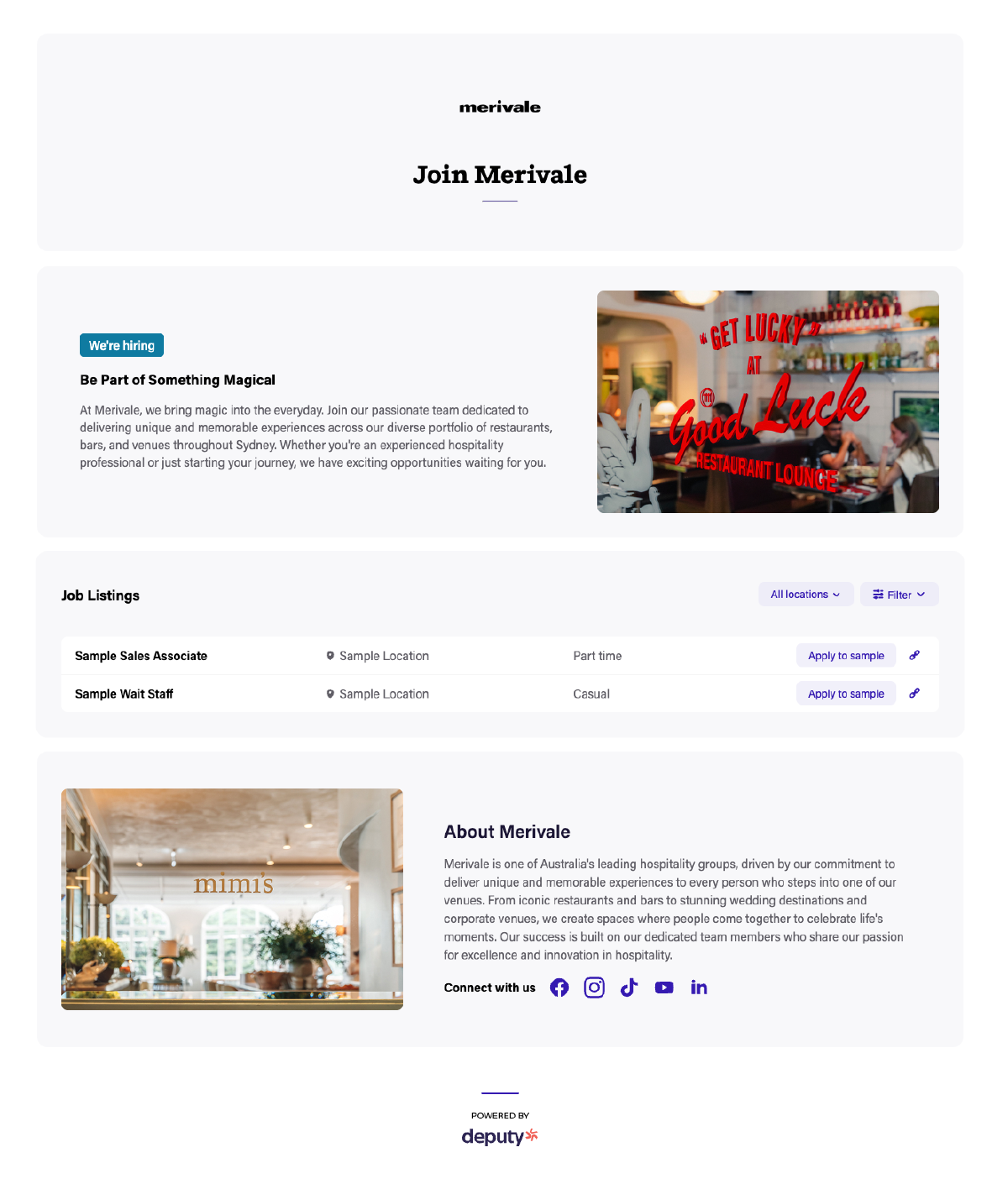
Merivale’s auto-generated careers page.
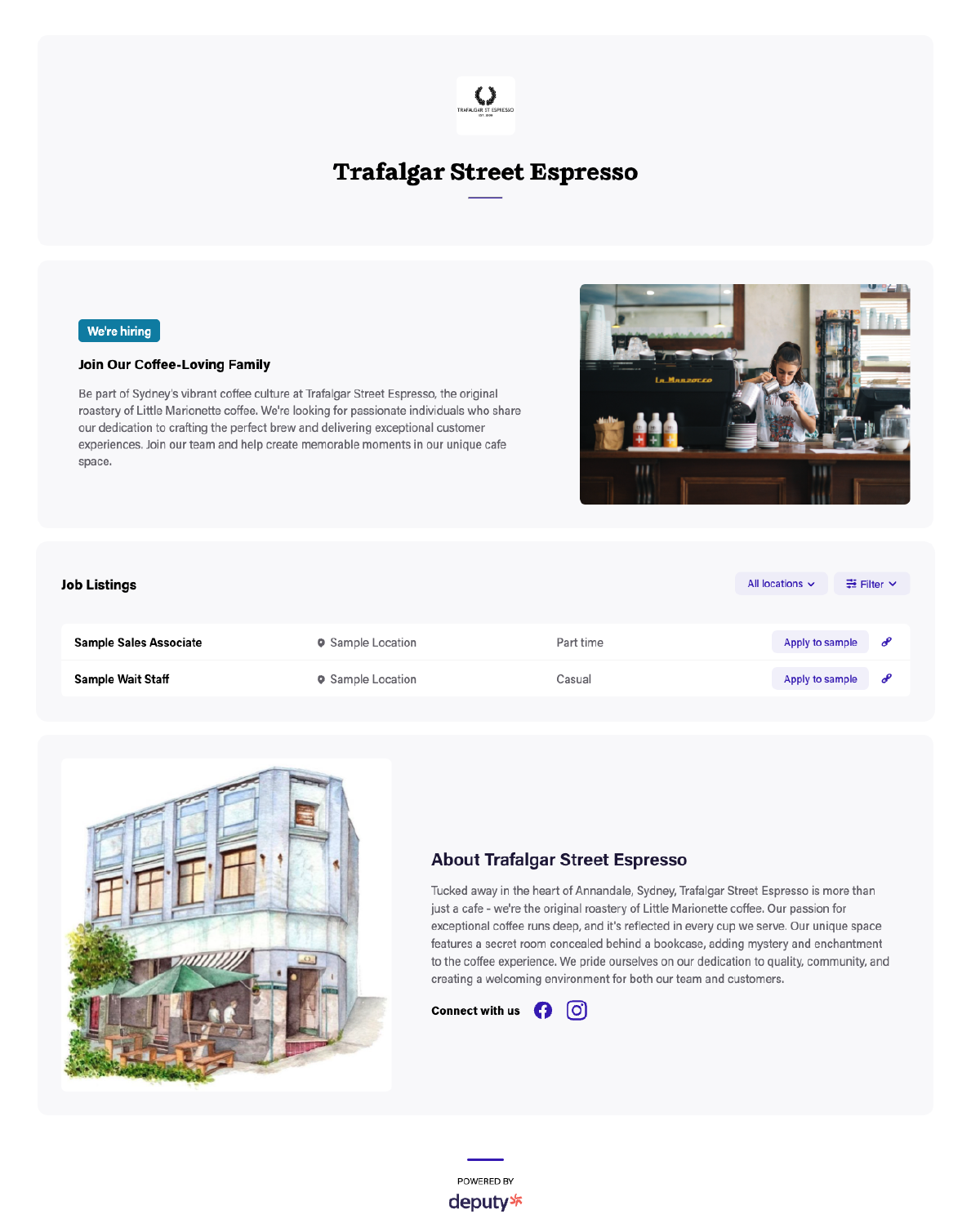
Trafalgar Street Espresso’s auto-generated careers page.
Reflection and final comments
Although we didn’t take home any awards, the project was still a success in validating the feasibility of auto-generating careers pages. We’ve learned valuable lessons by solving this problem, and are excited to explore its potential in future iterations.
Have you built something using generative AI? What challenges did you face? Let me know at arie@less.coffee or leave a comment.
Credits
I am grateful for my hackathon team at Deputy:
- Natasha (PM) and Paula (PD) for their product- and customer-conscious input, data collection, and for the visual cohesion of the final presentation (which is featured in the slides of this article).
- Yooshin (FE Engineer) and Toby (Website/FE Engineer) for their teamwork and collaboration on the engineering side, thanks to them we could bring it all together.
Appendix
Lambda source code
-
We don’t have any data to quantify that. We are just crossing our fingers. ↩︎